Storage
EMC VNX – MCx Hot Sparing Considerations
MCx has brought changes to the way Hot Sparing works in a VNX Array. Permanent Sparing is now the method used when a drive fails. How Permanent Sparing works: when […]
Virtualization & Storage

MCx has brought changes to the way Hot Sparing works in a VNX Array. Permanent Sparing is now the method used when a drive fails. How Permanent Sparing works: when […]
MCx has brought changes to the way Hot Sparing works in a VNX Array. Permanent Sparing is now the method used when a drive fails. How Permanent Sparing works: when a drive fails in a Raid Group (Traditional RG or Pool internal private RG) the RG rebuilds to a suitable spare drive in the VNX, this used Spare drive now becomes a permanent member of the RG. When the failed drive gets replaced then it becomes a Spare for eligible drives within the entire VNX Array. This new method of sparing eliminates the previous method used by Flare where the Hot Spare would equalize back to the original drive location (B_E_D) once the drive had been replaced.
Note: The rebuild does not initiate until 5 minutes after the drive has been detected as failed.
If you still prefer to keep the original physical Raid Group drive layout intact after the failed drive has been replaced then you can do a manual CopyToDisk from the original spare (which is now a member of the Raid Group) to the replaced drive by issuing the following navi command:
naviseccli –h SPA -user user -password password -scope 0 copytodisk sourcedisk destinationdisk
♦Source and Destination Disk = B_E_D format
For example to complete a manual CopyToDisk from source drive 2_0_14 to 2_0_0 then the following command would need to be run:
naviseccli –h SPA -user user -password password -scope 0 copytodisk 2_0_14 2_0_0
In addition to the CopyToDisk approach to keeping your original physical Raid Group B_E_D structures in place there is also another new MCx feature called Drive Mobility that allows you to swap the failed drive with the Spare that has been used as its replacement. For example you may have a failed drive in 2_0_0 which is part of a Raid_5(4+1) 2_0_0 – 2_0_4
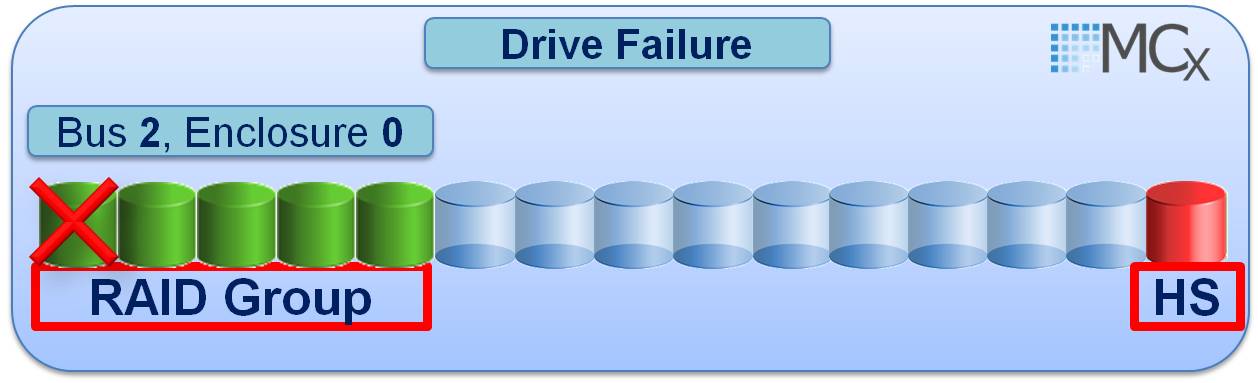
After the 5 min timer 2_0_0 gets automatically replaced by a suitable spare drive in slot 2_0_14 and the Raid Group is rebuilt:
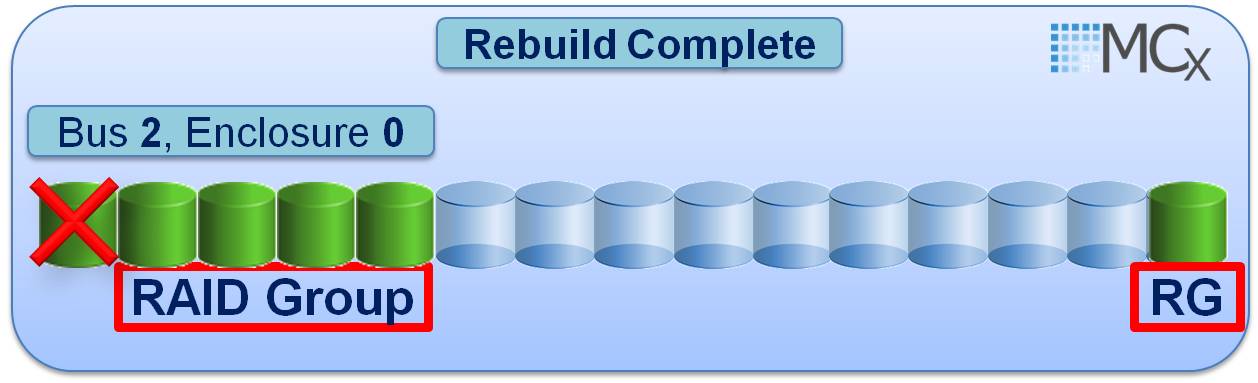
Once the rebuild is complete you may physically remove the drive in 2_0_14 and place it in 2_0_0 in order to restore your original Raid Group B_E_D structure (Once the drive is pulled from 2_0_14 then it must be relocated within 5 Minutes to slot 2_0_0 else a spare will be engaged to replace 2_0_14) Navicli can be used to ensure that the rebuild has 100% completed:
navicli -h SPA getdisk 2_0_14 -rb
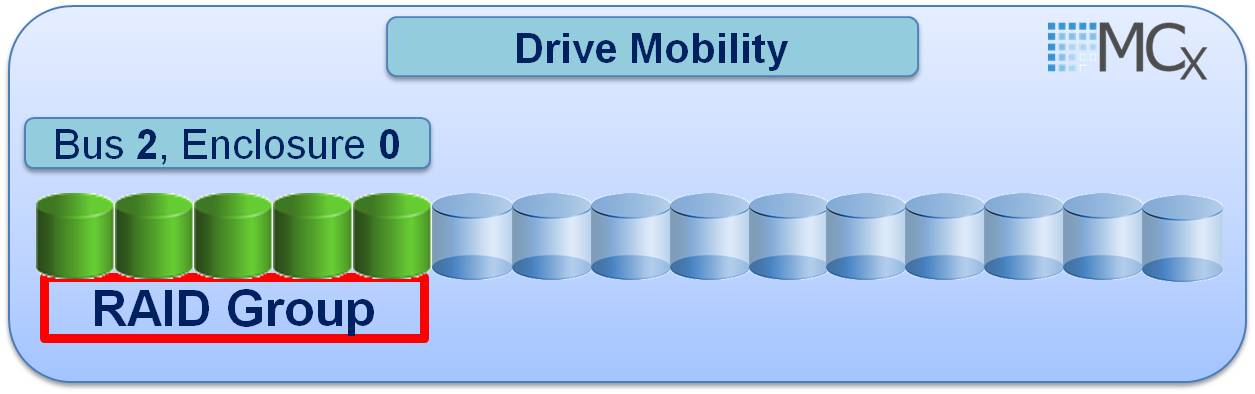
Spare location 2_0_14 is then replaced with a new drive:

You may wonder how this Drive Mobility is possible: With MCx when a Raid Group is created the drives within the Raid Group get recorded using the drives serial numbers rather than using the drives physical B_E_D location which was the FLARE approach. This new MCx approach of using the drives serial number is known as VD (Virtual Drive) and allows the drive to be moved to any slot within the VNX as the drive is not mapped to a specific physical B_E_D location but instead is recorded based on the drives serial number. Note: Vault drives 0_0_0 – 0_0_3 are excluded from any Drive Mobility and in fact if the Vault drives are 300 Gig in size then no spare is required, but if larger than 300G is used and user luns are present on the Vault then a spare is required in this case (To avoid alerts in Unisphere for not having the required spare drives available in relation to VAULT drives change the hot spare policy to custom and set the keep unused to 0).
While all un-configured drives in the VNX Array will be available to be used as a HS, a specific set of rules are used to determine the most suitable drive to use as a replacement for a failed drive:
1.Drive Type: All suitable drive types are gathered. (See matrix below)
2.Bus: Which of the suitable drives are contained within the same bus as the failing drive.
3.Size: Following on from the Bus query MCx will then select a drive of the same size or if none available then a larger drive will be chosen.
4.Enclosure: This is another new feature where MCx will analyse the results of the previous steps to check if the Enclosure that contains the actual Failing drive has a suitable replacement within the DAE itself.
Hot Spare Drive Matrix:
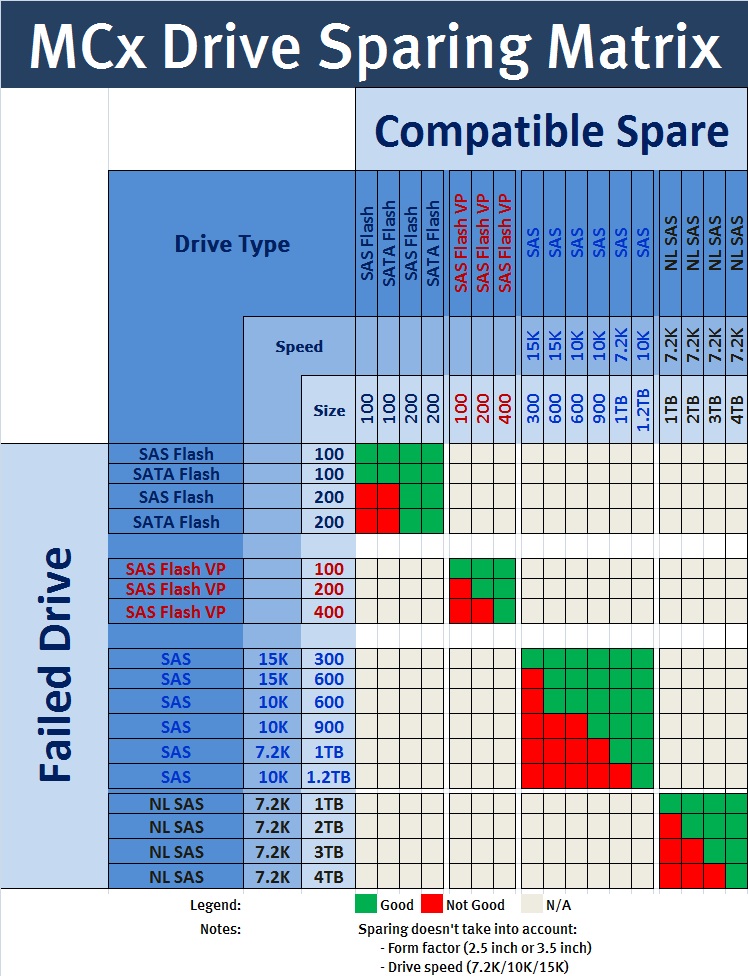
♦Here is a pdf download of the Matrix.
Best practice is to ensure 1 spare is available per 30 of each drive type. There is known bug with MCx Revision: 05.33.000.5.051 where recommended is displayed as 1/60 as you can see below, this is due to be fixed with the next release to reflect the 1/30 ratio. The three policy options are Recommended, Custom or NO Hot Spare. If the ‘No Hot Spare’ option is chosen this does not necessarily mean that no HS will be used, the system will spare to a drive in the system if a suitable match is found; this option just allows the user to configure all available drives of this type for use within Raid Groups. You can either use CLI or Unsphere to analyse the Policies defined on the array:
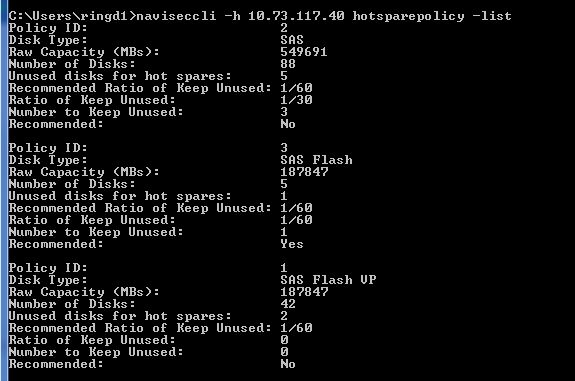
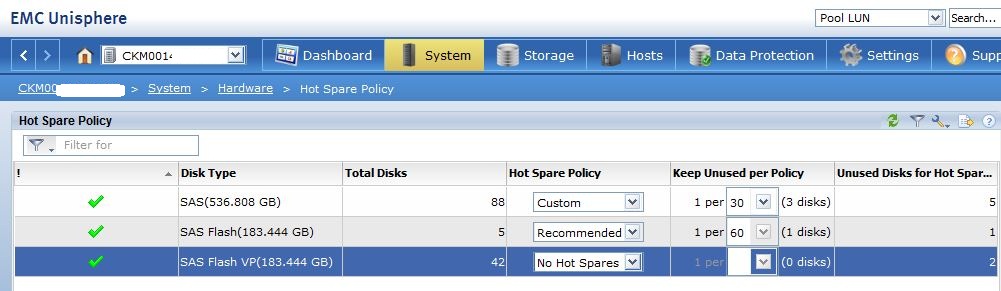
Also see Jon Klaus Post “VNX2 Hot Spare and Drive Mobility Hands-On”


There’s certainly a great deal to learn about this issue.
I like all of the points you have made.
Just curious I am building a config for a 5200 and unfortunately done have enough space to have the HS on each shelf. I do have the EFD spare on the DPE with the EFD pool. I then have the 10K HS on the DAE above the DAE with the 10K pool and raid group. I figured due to the drive mobility and algorithms. If a 10K fails it will go up a DAE and failover to it. I can then replace the drive with the drive mobility option. What kind of impact is their on the rebuild if the HS is on a separate DAE?
Not noticeable. Regards Dave
EMC should not ignore form factor. I understand their “we run everything” approach, but if you want to take advantage of teh DriveMobility feature, you cannot, if a 2.5″ has taken over for your failed 3.5″ drive. It forces you to use the copytodisk command to retain your original raid configuration layout. If you have a spare on every enclosure you may avoid this, but a 10+ enclosure unit will rarely have such a luxury.